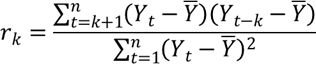(Thirty-fifth in a series)
In last week’s Forecast Friday post, we began our coverage of ARIMA modeling with a discussion of the Autocorrelation Function (ACF). We also learned that in order to generate forecasts from a time series, the series needed to exhibit no trend (either up or down), fluctuate around a constant mean and variance, and have covariances between terms in the series that depended only on the time interval between the terms, and not their absolute locations in the time series. A time series that meets these criteria is said to be stationary. When a time series appears to have a constant mean, then it is said to be stationary in the mean. Similarly, if the variance of the series doesn’t appear to change, then the series is also stationary in the variance.
Stationarity is nothing new in our discussions of time series forecasting. While we may not have discussed it in detail, we did note that the absence of stationarity made moving average methods less accurate for short-term forecasting, which led into our discussion of exponential smoothing. When the time series exhibited a trend, we relied upon double exponential smoothing to adjust for nonstationarity; in our discussions of regression analysis, we ensured stationarity by decomposing the time series (removing the trend, seasonal, cyclical, and irregular components), adding seasonal dummy variables into the model, and lagging the dependent variable. The ACF is another way of detecting seasonality. And that is what we’ll discuss today.
Recall our ACF from last week’s Forecast Friday discussion:

Because there is no discernable pattern, and because the lags pierce the ±1.96 standard error boundaries less than 5% (in fact, zero percent) of the time, this time series is stationary. Let’s do a simple plot of our time series:

A simple eyeballing of the time series plot shows that the series’ mean and variance both seem to hold fairly constant for the duration of the data set. But now let’s take a look at another data set. In the table below, which I snatched from my graduate school forecasting textbook, we have 160 quarterly observations on real gross national product:
|
160 Quarters of U.S. Real Gross Domestic Product |
|||||||
|
t |
Xt |
t |
Xt |
t |
Xt |
t |
Xt |
|
1 |
1,148.2 |
41 |
1,671.6 |
81 |
2,408.6 |
121 |
3,233.4 |
|
2 |
1,181.0 |
42 |
1,666.8 |
82 |
2,406.5 |
122 |
3,157.0 |
|
3 |
1,225.3 |
43 |
1,668.4 |
83 |
2,435.8 |
123 |
3,159.1 |
|
4 |
1,260.2 |
44 |
1,654.1 |
84 |
2,413.8 |
124 |
3,199.2 |
|
5 |
1,286.6 |
45 |
1,671.3 |
85 |
2,478.6 |
125 |
3,261.1 |
|
6 |
1,320.4 |
46 |
1,692.1 |
86 |
2,478.4 |
126 |
3,250.2 |
|
7 |
1,349.8 |
47 |
1,716.3 |
87 |
2,491.1 |
127 |
3,264.6 |
|
8 |
1,356.0 |
48 |
1,754.9 |
88 |
2,491.0 |
128 |
3,219.0 |
|
9 |
1,369.2 |
49 |
1,777.9 |
89 |
2,545.6 |
129 |
3,170.4 |
|
10 |
1,365.9 |
50 |
1,796.4 |
90 |
2,595.1 |
130 |
3,179.9 |
|
11 |
1,378.2 |
51 |
1,813.1 |
91 |
2,622.1 |
131 |
3,154.5 |
|
12 |
1,406.8 |
52 |
1,810.1 |
92 |
2,671.3 |
132 |
3,159.3 |
|
13 |
1,431.4 |
53 |
1,834.6 |
93 |
2,734.0 |
133 |
3,186.6 |
|
14 |
1,444.9 |
54 |
1,860.0 |
94 |
2,741.0 |
134 |
3,258.3 |
|
15 |
1,438.2 |
55 |
1,892.5 |
95 |
2,738.3 |
135 |
3,306.4 |
|
16 |
1,426.6 |
56 |
1,906.1 |
96 |
2,762.8 |
136 |
3,365.1 |
|
17 |
1,406.8 |
57 |
1,948.7 |
97 |
2,747.4 |
137 |
3,451.7 |
|
18 |
1,401.2 |
58 |
1,965.4 |
98 |
2,755.2 |
138 |
3,498.0 |
|
19 |
1,418.0 |
59 |
1,985.2 |
99 |
2,719.3 |
139 |
3,520.6 |
|
20 |
1,438.8 |
60 |
1,993.7 |
100 |
2,695.4 |
140 |
3,535.2 |
|
21 |
1,469.6 |
61 |
2,036.9 |
101 |
2,642.7 |
141 |
3,577.5 |
|
22 |
1,485.7 |
62 |
2,066.4 |
102 |
2,669.6 |
142 |
3,599.2 |
|
23 |
1,505.5 |
63 |
2,099.3 |
103 |
2,714.9 |
143 |
3,635.8 |
|
24 |
1,518.7 |
64 |
2,147.6 |
104 |
2,752.7 |
144 |
3,662.4 |
|
25 |
1,515.7 |
65 |
2,190.1 |
105 |
2,804.4 |
145 |
2,721.1 |
|
26 |
1,522.6 |
66 |
2,195.8 |
106 |
2,816.9 |
146 |
3,704.6 |
|
27 |
1,523.7 |
67 |
2,218.3 |
107 |
2,828.6 |
147 |
3,712.4 |
|
28 |
1,540.6 |
68 |
2,229.2 |
108 |
2,856.8 |
148 |
3,733.6 |
|
29 |
1,553.3 |
69 |
2,241.8 |
109 |
2,896.0 |
149 |
3,781.2 |
|
30 |
1,552.4 |
70 |
2,255.2 |
110 |
2,942.7 |
150 |
3,820.3 |
|
31 |
1,561.5 |
71 |
2,287.7 |
111 |
3,001.8 |
151 |
3,858.9 |
|
32 |
1,537.3 |
72 |
2,300.6 |
112 |
2,994.1 |
152 |
3,920.7 |
|
33 |
1,506.1 |
73 |
2,327.3 |
113 |
3,020.5 |
153 |
3,970.2 |
|
34 |
1,514.2 |
74 |
2,366.9 |
114 |
3,115.9 |
154 |
4,005.8 |
|
35 |
1,550.0 |
75 |
2,385.3 |
115 |
3,142.6 |
155 |
4,032.1 |
|
36 |
1,586.7 |
76 |
2,383.0 |
116 |
3,181.6 |
156 |
4,059.3 |
|
37 |
1,606.4 |
77 |
2,416.5 |
117 |
3,181.7 |
157 |
4,095.7 |
|
38 |
1,637.0 |
78 |
2,419.8 |
118 |
3,178.7 |
158 |
4,112.2 |
|
39 |
1,629.5 |
79 |
2,433.2 |
119 |
3,207.4 |
159 |
4,129.7 |
|
40 |
1,643.4 |
80 |
2,423.5 |
120 |
3,201.3 |
160 |
4,133.2 |
Reprinted from Introductory Business & Economic Forecasting, 2nd Ed., Newbold, P. and Bos, T., Cincinnati, 1994, pp. 362-3.
Let’s plot the series:

As you can see, the series is on a steady, upward climb. The mean of the series appears to be changing, and moving upward; hence the series is likely not stationary. Let’s take a look at the ACF:

Wow! The ACF for the real GDP is in sharp contrast to our random series example above. Notice the lags: they are not cutting off. Each lag is quite strong. And the fact that most of them pierce the ±1.96 standard error line is clearly proof that the series is not white noise. Since the lags in the ACF are declining very slowly, that means that terms in the series are correlated several periods in the past. Because this series is not stationary, we must transform it into a stationary time series so that we can build a model with it.
Removing Nonstationarity: Differencing
The most common way to remove nonstationarity is to difference the time series. We talked about differencing in our discussion on correcting multicollinearity, and we mentioned quasi-differencing in our discussion on correcting autocorrelation. The concept is the same here. Differencing a series is pretty straightforward. We subtract the first value from the second, the second value from the third, and so forth. Subtracting a period’s value from its immediate subsequent period’s value is called first differencing. The formula for a first difference is given as:

Let’s try it with our series:
When we difference our series, our plot of the differenced data looks like this:

As you can see, the differenced series is much smoother, except towards the end where we have two points where real GDP dropped or increased sharply. The ACF looks much better too:

As you can see, only the first lag breaks through the ±1.96 standard errors line. Since it is only 5% of the lags displayed, we can conclude that the differenced series is stationary.
Second Order Differencing
Sometimes, first differencing doesn’t eliminate all nonstationarity, so a differencing must be performed on the differenced series. This is called second order differencing. Differencing can go on multiple times, but very rarely does an analyst need to go beyond second order differencing to achieve stationarity. The formula for second order differencing is as follows:



We won’t show an example of second order differencing in this post, and it is important to note that second order differencing is not to be confused with second differencing, which is to subtract the value two periods prior to the current period from the value of the current period.
Seasonal Differencing
Seasonality can greatly affect a time series and make it appear nonstationary. As a result, the data set must be differenced for seasonality, very similar to seasonally adjusting a time series before performing a regression analysis. We will discuss seasonal differencing later in this ARIMA miniseries.
Recap
Before we can generate forecasts upon a time series, we must be sure our data set is stationary. Trend and seasonal components must be removed in order to generate accurate forecasts. We built on last week’s discussion of the autocorrelation function (ACF) to show how it could be used to detect stationarity – or the absence of it. When a data series is not stationary, one of the key ways to remove the nonstationarity is through differencing. The concept behind differencing is not unlike the other methods we’ve used in past discussions on forecasting: seasonal adjustment, seasonal dummy variables, lagging dependent variables, and time series decomposition.
Next Forecast Friday Topic: MA, AR, and ARMA Models
Our discussion of ARIMA models begins to hit critical mass with next week’s discussion on moving average (MA), autoregressive (AR), and autoregressive moving average (ARMA) models. This is where we begin the process of identifying the model to build for a dataset, and how to use the ACF and partial ACF (PACF) to determine whether an MA, AR, or ARMA model is the best fit for the data. That discussion will lay the foundation for our next three Forecast Friday discussions, where we delve deeply into ARIMA models.
*************************
What is your biggest gripe about using data? Tell us in our discussion on Facebook!
Is there a recurring issue about data analysis – or manipulation – that always seems to rear its ugly head? What issues about data always seem to frustrate you? What do you do about it? Readers of Insight Central would love to know. Join our discussion on Facebook. Simply go to our Facebook page and click on the “Discussion” tab and share your thoughts! While you’re there, be sure to “Like” Analysights’ Facebook page so that you can always stay on top of the latest insights on marketing research, predictive modeling, and forecasting, and be aware of each new Insight Central post and discussions! You can even follow us on Twitter! So get this New Year off right and check us out on Facebook and Twitter!